SPECIAL PROJECTS
________
CAPTO – A method for understanding problem domain for data science project
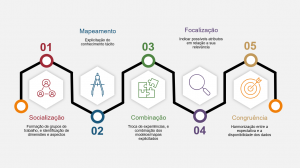
Data Science is an area where the objective is to infer scientific knowledge from facts and evidence expressed from data. Intrinsically, any data science project seeks knowledge typically by applying a knowledge discovery process (KDD). Regarding the attribute selection stage, there is a need to understand the application domain and the importance of a priori knowledge about this domain. However, in practice, not enough time is spent on understanding the domain, and consequently, the extracted knowledge may not be correct or not relevant. Considering that understanding the domain is an essential step in the KDD process, this work proposes the method called CAPTO to capture tacit knowledge about the domain, based on knowledge management models, and together with the available/acquired explicit knowledge, it proposes a strategy for building conceptual models to represent a problem domain. This model will contain the main dimensions (perspectives), aspects, and attributes that may be relevant to start a data science project. The conceptual model, obtained through the CAPTO method, can be used as an initial step for the conceptual selection of attributes, which can reduce the time spent in a knowledge discovery process.
Responsible: Luis E. Zárate
Model for predicting dropout of higher education students
Higher education institutions are becoming increasingly concerned with the retention of their students. This work is motivated by the interest in predicting and reducing student dropout, and consequently in reducing the financial loss of said institutions. From the characterization of the dropout problem, using educational data mining techniques through a process of knowledge discovery, a model (ensemble) is proposed with the objective of optimizing dropout prediction and understanding the main business rules in order to assist management. For this purpose, in the ensemble model, through a combination of results, three other models were considered: Logistic Regression, Neural Networks, and Decision Tree. As a result, it was possible to conclude that the ensemble model is able to correctly classify 89% of the students and to accurately identify 98.1% of the possible dropouts.
Responsible: Luis E. Zárate
Temporal Mining of Extreme Outliers
Outliers are data that differ from all others in a given probability distribution and can be identified in industrial environments, epidemiological control, financial fraud, environmental disasters, the IoT (Internet of Things), and others. The current literature considers the use of time series as the ideal modeling to treat a sensor system, which is also suitable for monitoring these sensors and detecting outliers to identify the emergence of estimated outliers as extremes, i.e., outliers with a high level of criticality and ability to have a high impact due to your surprise factor. However, it is possible to make estimations before such events may occur. Extreme outlier events occur with low frequency, making complex models that perform efficient predictions, as these models tend to fail due to the lack of or no representativeness that correctly characterizes events such as extreme outliers. In this paper, we propose a method for identifying extreme outliers from the continuously monitored sensor systems to recognize common outlier behavior patterns that tend to achieve critical operation levels. In addition, our approach also describes what can happen when such phenomena are about to emerge, and we seek to explain the temporal evolution of these phenomena to make the decision-making process more effective.
Responsible: Luis E. Zárate
Attribute selection based on causality analysis – LUISA algorithm proposal based on parental extension
The continuous growth of the volume of the data sets demands efficient methods of dimensionality reduction, especially feature selection methods. The non-casual methods of the selection of attributes may incur errors in terms of attribute relevance because they use one selection criteria that can lead to spurious correlations. On the other hand, the current causality methods of the attribute selections consider only the attributes that compose the Markov Blanket of one variable as relevant. This may lead to disregarding the attributes in the function, for example, the observational equivalence of Markov. This article presents a new algorithm based on the relationship of causality among variables that make the expansion of the Markov Blanket include indirect ancestors and a given variable target. The algorithm has been tested in ten databases three synthetic and seven real. After the feature selection performed by LUISA, the reduced real data sets were submitted to the classifiers Random Forest and Naive Bayes to match the accuracy with the complete base and with other causal and non-causal methods of the attribute selection. The results obtained show that the algorithm proposed in this article selected the relevant features in the synthetic data sets and a reduced number of attributes when compared to other methods of feature selection. In addition, the classifiers showed good results when using the data set reduced by LUISA when compared to the full data set and with other methods to select the attributes.
Responsible: Luis E. Zárate
Triadic Concept Approximation
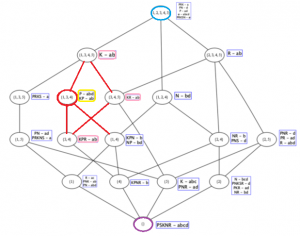
Formal Concept Analysis is a mathematical theory for knowledge representation as well as data analysis and visualization. It provides a mechanism for understanding and mining data through concept lattice construction and exploration. This theory assists in data processing by providing a framework for applying different analysis techniques. One of its potentials lies in its mathematical foundation that enables the generation, ordering, and visualization of knowledge in the form of formal concepts described in a hierarchy known as a concept lattice. However, as the input dataset grows, the search and especially the visualization and exploration of concepts becomes prohibitive. With the extension of the classical FCA approach to Triadic Concept Analysis, this problem becomes even more evident due to the complexity of the inherent structures in triadic concepts and relationships. In this work, we propose an approach to find triadic concepts when a query in the form of a triple is given, allowing the visualization and exploration of a Hasse diagram of triadic concepts.
Responsible: Mark A. Song
Approaches to knowledge acquisition based on Triadic Formal Concept Analysis
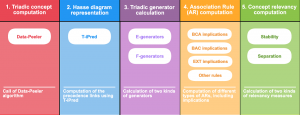
Formal Concept Analysis models problems through binary relations, in which it is indicated that certain objects have or not have certain attributes. However, in some scenarios, it is more natural to consider a three-dimensional representation, in which an additional set of conditions is introduced during modeling given certain conditions. Although there are several studies about new investigations and applications in Triadic Analysis of Concepts (TCA), in most cases, the original triadic context is flattened to a dyadic representation to then perform knowledge extraction. This approach can become extremely inefficient when the size of the triadic context grows, considering that the projection is performed through the Cartesian product between the set of attributes and the set of conditions. To overcome this limitation it is possible to explore the original triadic context without the need to flatten it. One possibility is to implement a set of algorithms in TCA to build the Hasse diagram of triadic concepts, computational generators, and association rules, including implications.
Responsible: Mark A. Song
Case Studies in the Health Area with Application of Triadic Formal Concept Analysis
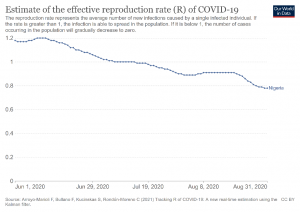
The health area presents several problems that demand the use of methods that produce a relevant and consistent analysis of the collected data. Through the Formal Analysis of Concepts, applying the triadic approach, called TCA, it is possible to evaluate the data by visualizing concepts and rules that allow us to explain and understand the evolution of the data along the collection waves. The results obtained from this research can help governments and entities in the development of better public policies to combat diseases. Several situations are analyzed in this project, such as the study of the evolution of antiemetic treatment, the characterization of infant mortality and a longitudinal study of COVID-19.
Responsible: Mark A. Song
SciBR-M: A method to map the evolution of scientific interest – A case study in Educational Data Mining
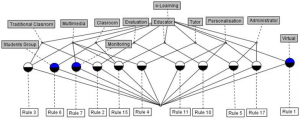
The scientific community shares a heritage of knowledge generated by several research fields. Identifying how scientific interest evolves is relevant for recording and understanding research trends and society’s demands. This article presents SciBR-M, a novel method to identify scientific interest evolution from bibliographical material based on Formal Concept Analysis. The SciBR-M aims to describe the thematic evolution surrounding a field of research. The method begins by hierarchically organising sub-domains within the field of study to identify the more relevant themes. After this organisation, we apply a temporal analysis that extracts implication rules with minimal premises and a single conclusion, which helps observe the evolution of scientific interest in a specific field of study. To analyse the results, we consider support, confidence, and lift metrics to evaluate the extracted implications. We applied the SciBR-M method for the Educational Data Mining (EDM) field, considering 23 years since the first publications. In the digital libraries context, SciBR-M allows the integration of the academy, education, and cultural memory, concerning a study domain.
Responsible: Luis E. Zárate
OrgBR-M: a method to assist in organizing bibliographic material based on formal concept analysis—a case study in educational data mining
For conducting literature reviews necessary a preliminary organization of the available bibliographic material. In this project, we present a novel method called OrgBR-M (method to organize bibliographic references), based on the formal concept analysis theory, to assist in organizing bibliographic material. Our method systematizes the organization of the bibliography and proposes metrics to assist in guiding the literature review. As a case study, we apply the OrgBR-M method to perform a literature review of the educational data mining field of study.
Responsible: Luis E. Zárate
Effectively clustering researchers in scientific collaboration networks: case study on ResearchGate
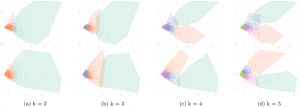
Social networks play a significant role in sharing knowledge. Scientific collaboration online networks allow scientific articles and research results to be shared, and the interaction and possible collaboration between researchers. These networks have many users and store varied data about each of them, and which of the data are used to characterize and group similar users? The number of attributes available about each instance (user) can reach several hundred, making this a problem with high dimensionality. Thus, dimensionality reduction is indispensable to remove redundant and irrelevant attributes to improve machine learning algorithms’ performance and make models more understandable. In order to produce an efficient recommendation system for collaborative research, one of the main challenges of dimensionality reduction techniques is guaranteeing that the information of the data is represented in the reduced dataset after the reduction. In our dimensionality reduction, we used Factor Analysis, as it preserves the relationships between the variables. In this study, we characterize the profiles of ResearchGate users after applying dimensionality reduction to two different datasets. A dataset of continuous attributes composed of profile metrics and a dataset of dichotomous attributes contained interest topics. We evaluated our methodology using two recommendation applications: (1) Identifying groups of researchers through a global profile extraction process; and (2) Identifying profiles similar to a reference profile. For both applications, we used hierarchical clustering techniques to identify the groups of user profiles. Our experiments show that the Factor Analysis transformation was able to preserve the relevant information in the data, resulting in an effective clustering process for the recommendation system for collaborative networks of researchers.
Responsible: Luis E. Zárate
Extreme precipitation prediction based on neural network model – A case study for southeastern Brazil
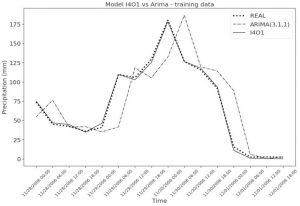
Extreme rainfall events can devastate urban and rural infrastructure, affect the economy and even lead to loss of life. In this work, we propose an approach based on Long Short Term Memory Networks (LSTM) to forecast precipitation volume extreme rainfall using multivariate time series data. Our methodology combines reanalysis data from 12 isobaric pressure levels, surface data, and data from meteorological stations in Brazil’s southeastern region. Our method allows handling the imbalanced data typical of time-series data used for this type of problem. In order to identify the best model, we performed several experiments with different configurations of LSTM networks. The test results showed that the best prediction model has as input previous data up to 24 hours for a forecast of 6 hours ahead with a mean absolute error (MAE) of 6.9 mm and root mean squared error (RMSE) of 6.94 mm. Our methodology shows the possibility to use reanalysis data from global mathematical models to obtain less computationally expensive regional models.
Responsible: Luis E. Zárate
Algoritmo genético multiobjetivo para seleção de atributos aplicado em bioinformática
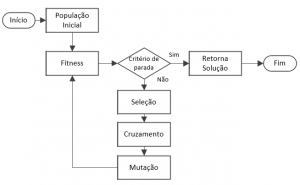
With the recent advances of genomic sequencing techniques, the number of protein sequences available for analysis has increased greatly. Wet-lab processes to predict the function of a protein are too high-cost to answer to this demand. However, knowing the function of a protein is extremely important in several fields such as medicine and agriculture. Therefore, it is necessary to find computational models able to predict protein function. That is an open research field in Bioinformatics, since the existing models don’t perform well enough yet. The Sting DB database gathers relevant information related to the proteins’ physico-chemical characteristics, which have been considered in some research, most of those limited to a few set of characteristics. In this work, we proposed a methodology utilizing a multi-objective genetic algorithm to find the ideal subset of characteristics to identify the classes of a dataset of enzymes. After the feature selection process, we performed a dataset enhancement by adding new variables, in order to construct a SVM classifier. The proposed methodology achieved 77.3% precision and 72.6% F-Measure averages. A previous analysis showed that there were variables with a certain level of correlation. In order to verify if the correlation influenced the result, we used the technique of AF. This approach obtained precision values of 71.9% and F-Measure of 65.6%.
Responsible: Luis E. Zárate
Formal concept analysis for online professional social networks analysis
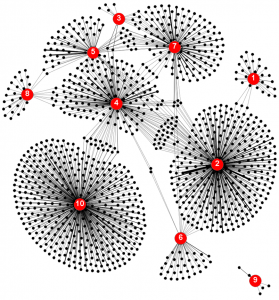
From the recent proliferation of online social networks, a set of specific types of social networks is attracting more and more interest from people all around the world. It is a professional social network, where the users’ interest is oriented to business. The behavior analysis of this type of user can generate knowledge about competencies that people have developed in their professional careers. In this scenario, and considering the available amount of information in professional social networks, it has been fundamental the adoption of effective computational methods to analyze these networks. The formal concept analysis (FCA) has been an effective technique for social network analysis (SNA), because it allows identifying conceptual structures in data sets, through the conceptual lattice and implication rules. Particularly, a specific set of implications rules, known as proper implications, can represent the minimum set of conditions to reach a specific goal. In this work, we proposed a FCA-based approach to identify relations among professional competencies through proper implications. The experimental results, with professional profiles from LinkedIn and proper implications extracted from PropIm algorithm, show the minimum sets of skills that are necessary to reach job positions.
Responsible: Luis E. Zárate
Minimal Implications Base for Social Network Analyzes
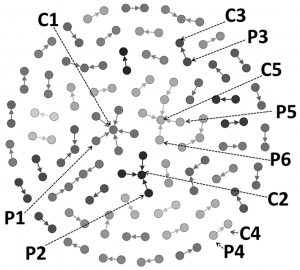

Currently, social network (SN) analysis is focused on the discovery of activity and social relationship patterns. Usually, these relationships are not easily and completely observed, so, it is relevant to discover substructures and potential behavior patterns in SN. Recently the formal concept analysis (FCA) has been applied for this purpose. The FCA is a concept analysis theory which identi_es concept structures within a data set. The representation of SN patterns through implication rules based on FCA enables to identify relevant substructures that cannot be easily identi_ed. Our approach considers a minimum and irreducible set of implication rules (stem base) to represent the complete set of data (activity in the network). Applying it to a social network is of interest because it can represent all the relationships using a reduced form.
Responsible: Luis E. Zárate
Classifying longevity profiles through longitudinal data mining

Population researches on human ageing often generate longitudinal datasets with high dimensionality. In order to discover knowledge in such datasets, the traditional knowledge discovery in database task needs to go through some adaptations. This is necessary, in order to benefit from the advantages of the longitudinal data and to tackle the issues that it brings. In this article, we have presented a full knowledge discovery process that was performed upon a longitudinal dataset, while discussing the singularities of this process and approaches to address these singularities. We performed data preparation processes on datasets created from the English Longitudinal Study of Ageing’s database, and employed semi-supervised learning on a dataset that was comprised of records from short-lived and long-lived individuals. By using clusters with a majority of the members from each class as training sets, we then employed a decision tree algorithm to classify the study’s respondents and describe the profiles of each class. The results have shown influences from several different aspects in the differentiations between the classes’ profiles, including economic, social, and health-related attributes. The findings have pointed towards a need to further investigate these relationships, between the attributes from these different aspects and how they have contributed to the comprehension of how the environment can affect the lifespan of an individual. Besides, this methodology and the adopted procedures can be applied to any other longitudinal studies of ageing.
Responsible: Luis E. Zárate
Representation and Control of the Cold Rolling Process through Artificial Neural Networks via Sensitivity Factors

The mathematical modeling of the rolling process involves several parameters that may lead to non-linear equations of the difficult analytical solution. Such is the case of Alexander’s model (Alexander 1972), considered one of the most complete in the rolling theory. This model requires significant computational time, which prevents its application in on-line control and supervision systems. For this reason, new and efficient forms to represent this kind of process are still necessary. The only requirement is that the new representations incorporate the qualitative behavior of the process and that they can be used in the control system design. In this paper, the representation of the cold rolling process through Neural Networks, trained with data obtained by Alexander’s model, is presented. Two neural networks are trained to represent the rolling process and operation. For them, the quantitative and qualitative aspects of their behaviors are verified through simulation and sensitivity equations. These equations are based on sensitivity factors obtained by differentiating the previously trained neural networks; and for different operation points, different equations can be obtained with low computational time. On the other hand, one of the capital issues in the controller design for rolling systems is the difficulty to measure the final thickness without time delays. The time delay is a consequence of the location of the output thickness sensor which is always placed a certain distance ahead of the roll-gap region. The representation based on sensitivity factors has predictive characteristics that will be used by the control strategy. This predictive model permits overcoming the time delay that exists in such processes and can eliminate the thickness sensor, usually based on X-ray. This model works as a virtual sensor implemented via software. Besides, this paper presents a method to determine the appropriate adjustment for thickness control considering three possible control parameters: roll gap, and front, and back tensions. The method considers the best control action, the one that demands the smallest adjustment. Simulation results show the viability of the proposed techniques and an example of the application to a single-stand rolling mill is discussed.
Responsible: Luis E. Zárate
Sensitivity Analysis of Cause-Effect Relationship Using Neural Networks
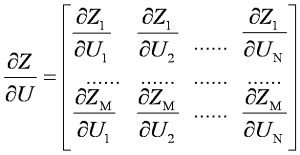
Many industrial, chemical, economic, and financial processes have non-linear characteristics and intrinsic complexities that hinder the development of mathematical models. Through a mathematical model is possible to obtain knowledge of the cause-effect relationship of the variables. The relationship between the parameters of the process can be expressed by sensitivity factors. If these sensitivity factors are calculated through the differentiation of complex mathematical models this may lead to equations of the difficult analytic solutions. In this work, a technique for obtaining the sensitivity factors is proposed. In this technique, the sensitivity factors are obtained by differentiating a neural network previously trained. The expressions to calculate the sensitivity factors are generic for nets multi-layer with N entries, M exits and L neurons in the hidden layer. Each sensitivity factor that relates one parameter A (cause) with one parameter B (effect) allows identifying which entries (cause) present a larger influence in the exit (effect) of the process. This way, this technique allows to the identification of the parameters that should be observed and controlled during the productive activity. Finally, an application for the strip rolling process is presented.
Responsible: Luis E. Zárate
Hybrid Structure based on Previous Knowledge and GA to Process
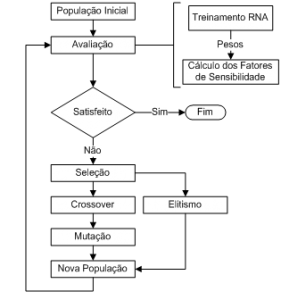
Description: The neural representation of a physical process has the objective of explaining the cause-effect relationship among the parameters involved in the process. The representation is normally evaluated through the error reached during the training and validation processes. As the neural representation is not based on physical principles, its mathematical representation can be correct in the quantitative aspect but not in the qualitative one. In this work, it is shown that a neural representation can fail when its qualitative aspect is evaluated. The search for the ideal neuron quantity for the hidden layer of the MLP neural network, by means of Genetic Algorithms and the sensitivity factors calculated directly from the neural networks during the training process, is presented. The new optimization structure has the objective to find a neural network structure capable to represent the process quantitatively and qualitatively. The sensitivity factors, when compared with the expert knowledge of the human agent, represented through symbolic rules, can evaluate not only the quantitative but also the qualitative aspect of the process being represented through a specific neural structure. The results obtained, and the time (epochs) necessary to reach the neural network target show that this combination is promising. As a case study, the new structure is applied to the cold rolling process.
Responsible: Luis E. Zárate
Climatic Data Neural Representation for Large Territorial Extensions: Case Study for the State of Minas Gerais
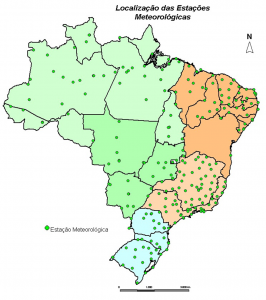
It is possible to observe that for large areas the number of meteorological stations is small or they are improperly distributed. In environments or systems whose climatic variables impact directly or indirectly in production, it is necessary to know or at least be able to estimate climate data to improve the production of the processes. To meet this demand, in this paper a representation of weather data for large areas through artificial neural networks (ANN) is proposed. All the procedures adopted are detailed which allows being used to represent other regions. The main input variables of the neural model are latitude, longitude, and altitude.
Responsible: Luis E. Zárate
Neural Representation to estimate the Relative Air Humidity
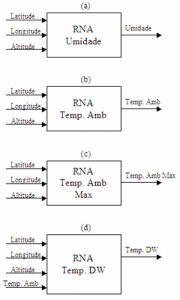
To obtain the neural model, the historical climate data on a daily basis was considered for 12 years from 1995 to 2006 from 255 weather stations located in the Brazilian territory. Based on the observed data over this period, a neural representation for each month of the year was proposed for the variables: latitude (lat), longitude (long), elevation (elev), maximum temperature (Tmax), minimum temperature (tmin) with the relative air humidity (UR).
Responsible: Luis E. Zárate
FCANN: A new approach for extraction and representation of knowledge from ANN trained via Formal Concept Analysis
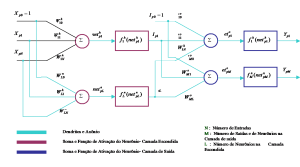
Nowadays, Artificial Neural Networks (ANN) are being widely used in the representation of different systems and physics processes. Once trained, the networks are capable of dealing with operational conditions not seen during the training process, keeping tolerable errors in their responses. However, humans cannot assimilate the knowledge kept by those networks, since such implicit knowledge is difficult to be extracted. In this work, Formal Concept Analysis (FCA) is being used in order to extract and represent knowledge from previously trained ANN. The new FCANN approach permits to obtain a complete canonical base, non-redundant and with minimum implications, which qualitatively describes the process being studied. The approach proposed has a sequence of steps such as the generation of a synthetic dataset. The variation of data number per parameter and the discretization interval number is adjustment factors to obtain more representative rules without the necessity of retraining the network. The FCANN method is not a classifier itself as other methods for rule extraction; this approach can be used to describe and understand the relationship among the process parameters through implication rules. Comparisons of FCANN with C4.5 and TREPAN Algorithms are made to show its features and efficacy. Applications of the FCANN method for real-world problems are presented as case studies.
Responsible: Luis E. Zárate
Qualitative Behavior Rules for the Cold Rolling Process Extracted from Trained ANN via FCANN Method
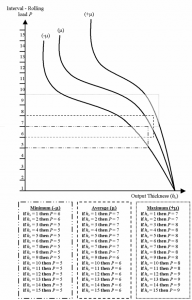
Nowadays, Artificial Neural Networks (ANN) are being widely used in the representation of different systems and physics processes. In this paper, a neural representation of the cold rolling process will be considered. In general, once trained, the networks are capable of dealing with operational conditions not seen during the training process, keeping acceptable errors in their responses. However, humans cannot assimilate the knowledge kept by those networks, since such knowledge is implicit and difficult to be extracted. For this reason, the Neural Networks are considered a “black box”. In this work, the FCANN method based on Formal Concept Analysis (FCA) is being used in order to extract and represent knowledge from previously trained ANN. The new FCANN approach permits to obtain a non-redundant canonical base with minimum implications, which qualitatively describes the process. The approach can be used to understand the relationship among the process parameters through implication rules in different operational conditions on the load curve of the cold rolling process. Metrics for evaluation of the rules extraction process are also proposed, which permit a better analysis of the results obtained.
Responsible: Luis E. Zárate
Genetic Identity Inference – An approach based on Symbolic Model Checking and Bayesian Networks
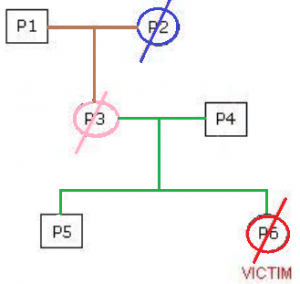
DNA testing has proven to be an extremely powerful technique in determining genetic identity. Among the cases that can be solved through the use of DNA analysis, we can mention the determination of paternity, identification of missing persons and exchanges of babies in maternity wards. DNA testing has also been used successfully in clarifying criminal cases, in confirming the identity of suspects or victims, for example, in murders and rapes. The determination of identity through DNA can be considered one of the most revolutionary products of modern human molecular genetics. Classic methods that usually include visual recognition, fingerprint identification, analysis of dental records and dental arches cannot always be used given the conditions in which the bodies are found. These cases are examples of large-scale disasters where DNA-based analysis should be applied. The attack on the twin towers of the World Trade Center on September 11, 2001 can be cited as one of the examples of tragedies involving thousands of deaths. It is estimated that the number of victims is around 2800 people. In a typical disaster scenario, there would be hundreds or thousands of bodies and fragments in which identification would only be possible by analyzing their DNAs. Therefore, the general objective of this work is to implement a computational environment that allows the application of Bayesian networks in the inference of kinship relations from the use of symbolic verification of models to reduce the space of solutions.
Responsible: Mark A. Song
Handling Large Formal Context using BDD – Perspectives and Limitations
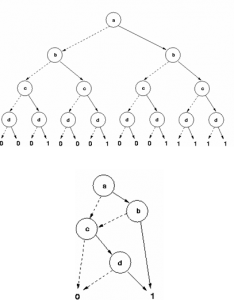
This paper presents Binary Decision Diagrams (BDDs) applied to Formal Concept Analysis (FCA). The aim is to increase the FCA capability to handle large formal contexts. The main idea is to represent formal context using BDDs for the latter extraction of the set of all formal concepts from this implicit representation. BDDs have been evaluated based on several types of randomly generated synthetic contexts and on density variations in two distinct occasions: (1) computational resources required to build the formal contexts in BDD; and (2) to extract all concepts from it. Although BDDs have had fewer advantages in terms of memory consumption for representing formal contexts, it has true potential when all concepts are extracted. In this work, it is shown that BDDs could be used to deal with large formal contexts especially when those have few attributes and many objects. To overcome the limitations of having contexts with fewer attributes, one could consider vertical partitions of the context to be used with distributed FCA algorithms based on BDDs.
Responsible: Luis E. Zárate
Data Mining Applied to the Discovery of Symptom Patterns is Data Base of Patients with Nephrolithiasis
Nephrolithiasis is a disease that is unknown yet a clinical treatment that determines the disease cure. The adult population is esteemed an incidence of around 5 to 12%, being a little lesser in the pediatric band. Renal colic, caused by nephrolithiasis, is the main disease symptom in adults and it is observed in 14% of pediatric patients. The disease symptoms in the pediatric patient don’t follow a pattern, and this difficult the disease diagnosis. The objective of this work is the discovery of patterns of the disease symptoms through the application of KDD methodology to determine discrimination rules for the patterns of the symptoms. The results and the conclusions of the work are presented at the end of the article.
Responsible: Luis E. Zárate
Data Mining in the Reduction of the Number of Places of Experiments for Plant Cultivates
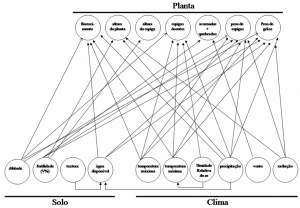
When a new plant cultivar is developed, it needs to be evaluated in relation to different environmental conditions before being commercially released. A set of experiments systematically was conducted at various locations with the purpose of evaluating the performance of the plants, in different soil, climate and elevation conditions. In these experiments, the plant culture development was monitored throughout the entire planting cycle. It is important to note that these experiments are very expensive and the aim of this work is to verify the possibility of reducing the number of places of the experiments without losing of representativeness in the evaluation of planted cultivars. To achieve this goal, the interaction among soil, climate and plant was modeled and the major components in each of these systems were considered. Neural computational models were also developed in order to estimate data regarding the relative air humidity. Using the partitioned clustering technique (k-medians), clusters (planting sites) were built in such a way that, according to the methodology proposed were similar in terms of soil, climate and plant behavior. The consistency of the formed clusters was evaluated by two criteria and the recommendation for reducing the cultivation sites was presented. By analyzing the results, it was possible to verify that the clustering process is not sufficient for deciding which planting locations should be omitted. It is necessary to count on complementary evaluation criteria associated with the production and cultivar ranking. In this work, the national competition experiments of maize cultivars in Brazil are considered as case study.
Responsible: Luis E. Zárate
Missing Value Recovering in Imbalanced Databases, Application in Marketing Databases with Massive Missing Data

Missing data in databases are considered to be one of the biggest problems faced by Data Mining application. This problem can be aggravated when there is massive missing data in the presence of imbalanced databases. Several techniques such as imputation, classifiers, and approximation of patterns have been proposed and compared, but these comparisons do not consider adverse conditions found in real databases. This work, it is presented a comparison of techniques used to classify records from a real imbalanced database with massive missing data, where the main objective is the database pre-processing to recover and select records completely filled for a further application of the techniques. It compared algorithms such as clustering, decision tree, artificial neural networks, and Bayesian classifier. Through the results, it can be verified that problem characterization and database understanding are essential steps for a correct technique comparison in a real problem. It was observed that artificial neural networks are an interesting alternative for this kind of problem since it is capable to obtain satisfactory results even when dealing with real-world problems.
Responsible: Luis E. Zárate
RAIMA: A new approach for identifying the missing value mechanism
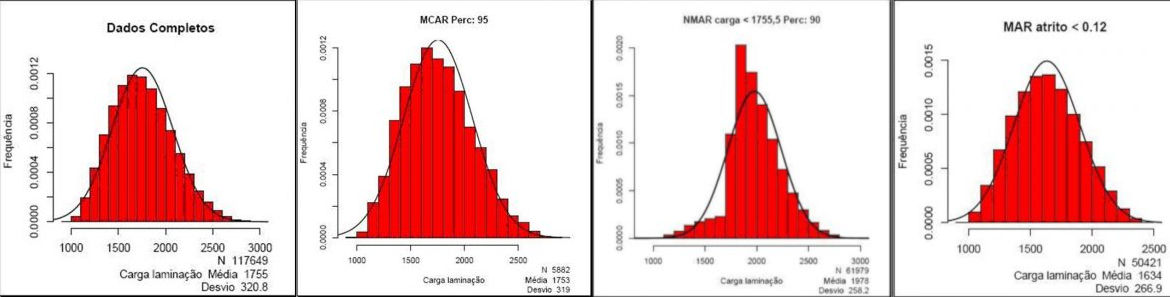
Missing data is one of the most significant problems encountered in real-world data mining and knowledge discovery projects. Many approaches have been proposed to deal with the missing values problem. These approaches are related to the missing mechanisms. However, it can be difficult to detect these mechanisms since in some situations they are not clear. Precise identification of the missing mechanism is crucial to the selection of appropriate methods for dealing with missing data and thus obtaining better results in the processes of data mining and knowledge discovery.
Responsible: Luis E. Zárate
SPHERE-M: an Ontology Capture Method
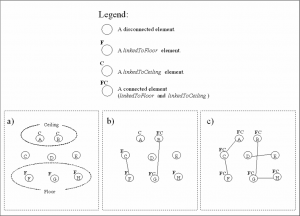
This project proposes a method to help the ontology capture task, and also the development of a computational tool that orients in its utilization, trying to give better technical and formal apparatus to this initial task on the ontology-building process. The presented method proposes rules, restrictions, steps, and metrics to be used in the capture task, helping this activity in an objective way, and adding more formalism and philosophical basis to the ontology-building methodologies.
Responsible: Luis E. Zárate
Prospects and limitations in the context of knowledge warehouse – Case study in social databases

Organizations use the techniques of data warehouse and knowledge discovery in databases to generate useful information to support their strategic decisions. These techniques, if properly combined, can offer a broad knowledge of business domain treaties. This project proposes the use of an ontology to organize and categorize the relevant data from the field of social vulnerability. With the exploration of this area will evaluate the prospects and limitations of using ontology as a basis for a model of data warehouse in relation to the wider area treated. Data on social vulnerability will be extracted from the foundations of social systems and CADUNICO and SIAB, which are made available by the federal government, in Brazil, and after implementation of this work will be possible to demonstrate new knowledge about the interrelationship between the systems in order to facilitate the view of the impacts that a government sector can have on other sectors.
Responsible: Luis E. Zárate
PICTOREA: A Method for Knowledge Discovery in Data Base
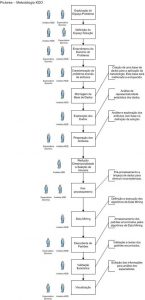
Nowadays, knowledge discovery in databases (Knowledge Discovery in Databases – KDD) is widely used in academia and yet little used in the market. Organizations using KDD process, usually do with acquiring software and methodologies defined by them. However, most KDD applications are made using a proprietary methodology for dealing with each case. These methodologies generally do not follow a pattern. Through the interpretive scientific method, concepts of Domain-Driven Data Mining – D3M, with the aid of Methodology for Process Modeling (Business Process Management – BPM) and SPEM – Software and Systems Process Engineering Meta-Model, this paper proposed a pedagogical canonical method called PICTOREA for developing, monitoring and documentation of the steps and activities of a project KDD.
Responsible: Luis E. Zárate
Characterization of Time Series for Analyzing of the Evolution of Time Series
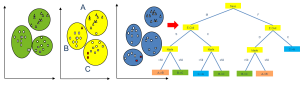
This work proposes a new approach for the characterization of time series in databases (Temporal Databases – TDB) for temporal analysis of clusters. For the characterization of the time series, it was used the level and trend components calculated through the Holt-Winters smoothing model. For the temporal analysis of those clusters, it was used in a combined manner the AGNES (Agglomerative Hierarchical Cluster) and PAM (Partition Clustering) techniques. For the application of this methodology, an R-based script for generating synthetic TDBs was developed. Our proposal allows the evaluation of the clusters, both in the object movement such as in the appearance or disappearance of clusters. The model chosen to characterize the time series is adequate because it can be applied for short periods of time in situations where changes should be promptly detected for quick decision-making.
Responsible: Luis E. Zárate
Improvement in the prediction of the translation initiation site through balancing methods, the inclusion of acquired knowledge, and the addition of features to sequences of mRNA
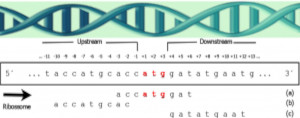
The accurate prediction of the initiation of translation in sequences of mRNA is an important activity for genome annotation. However, obtaining an accurate prediction is not always a simple task and can be modeled as a problem of classification between positive sequences (protein codifiers) and negative sequences (non-codifiers). The problem is highly imbalanced because each molecule of mRNA has a unique translation initiation site and various others that are not initiators. Therefore, this study focuses on the problem from the perspective of balancing classes and we present an undersampling balancing method, M-clus, which is based on clustering. The method also adds features to sequences and improves the performance of the classifier through the inclusion of knowledge obtained by the model, called InAKnow.
Responsible: Luis E. Zárate
Applying ANN to Model the Stock Market for Prediction of Stock Price and Improvement of the Direction Prediction Index — Case Study of PETR4 – Petrobras, Brazil
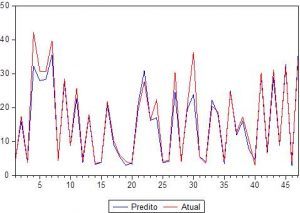
Predicting the direction of stock price changes is an important factor, as it contributes to developing effective strategies for stock market transactions and attracts much interest in incorporating historical variables series in the mathematical models or computer algorithms in order to produce predictions about the expectation of price changes. The purpose of this study is to build a neural model for the financial market, allowing predictions of future behavior of the closing prices of the stocks negotiated in BM&FBOVESPA in the short term, using the economic and financial theory, combining technical analysis, fundamental analysis and analysis of time series, so as to predict the behavior of prices, addressing the percentage of correct predictions about the direction of the price series (POCID). This work had the intention of understanding the information available in the financial market and indicating the variables that drive stock prices. The methodology presented may be adapted to other companies and their stock. The stock PETR4 of Petrobras, traded in BM&FBOVESPA, was used as a case study. As part of this effort, configurations with different window sizes were designed, and the best performance was achieved with a window size of 3, with a POCID index of correct direction predictions of 93.62%.
Responsible: Luis E. Zárate
Transductive SVM-based prediction of protein translation initiation site
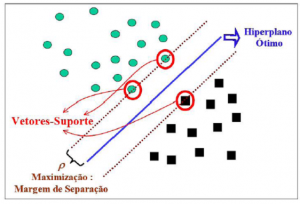
The correct protein-coding region identification is an important problem. This problem becomes more complex due to the unfamiliarity with both the biological context and the presence of conservative characteristics in the messenger RNA (mRNA). Therefore, it is fundamental to research computational methods aiming to help in the discovery of patterns within the Translation Initiation Sites (TIS). Literature has widely applied machine learning methods in inductive inference, primarily in the field of Bioinformatics. On the other hand, not so much focus has been given to transductive inference-based machine learning methods such as Transductive Support Vector Machine (TSVM). Transductive inference performs well for problems of text categorization, in which the amount of categorized elements is considerably smaller than the noncategorized ones. Similarly, the problem of predicting the TIS may take advantage of transductive methods due to the fact that the amount of new sequences grows rapidly with the progress of the Genome Project and the study of new organisms. Consequently, this work aims investigate the transductive learning towards predicting TIS and to compare its performance with the inductive inference in the following tools: TISHunter, TisMiner, and NetStart.
Responsible: Luis E. Zárate